Text watermarking algorithms play a vital role in protecting the copyright of written content. While these techniques have come a long way, recent advancements in large language models (LLMs) have opened up new possibilities. LLMs not only improve watermarking methods but also highlight the need to safeguard their own creations from misuse. In this survey, we take a closer look at the current landscape of text watermarking technology. Additionally, if you want to experience various watermarking algorithms in practice, you can visit the MarkLLM Project.
View PDFIn this survey, you will find information about the following four key areas:
Techniques Overview
We provide an overview and comparison of different text watermarking methods, categorizing them into two primary types: Watermarking for Existing Text and Watermarking for Large Language Models.
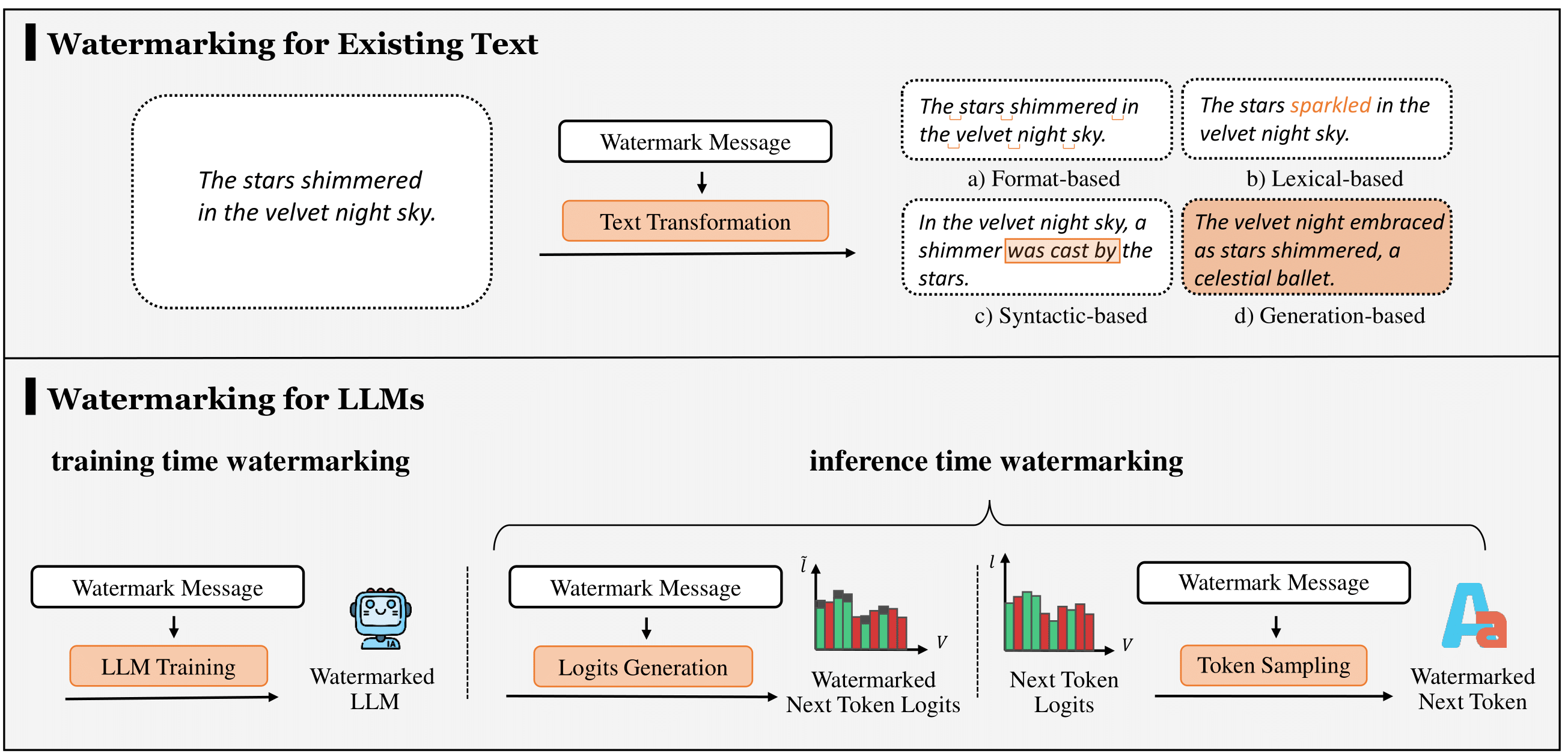
Fig. 1: Illustration of the two categories: Watermarking for Existing Text and Watermarking for LLMs.
- Watermarking for Existing Text embeds watermarks by post-processing pre-existing texts.
- Format-based Watermarking changes text format rather than its content to embed watermarks.
- Lexical-based Watermarking involves replacing selected words with their synonyms to embed watermarks.
- Syntactic-based Watermarking modifies the text's syntax structure to insert watermarks.
- Generation-based Watermarking utilizes neural networks to directly generate watermarked text given original text and watermark message.
- Watermarking for Large Language Models involves modifying LLMs and let LLMs directly produce watermarked text.
- Watermarking during Logits Generation involves modifying the LLM logits to embed watermarks.
- Watermarking during Token Sampling alters the token sampling process to add watermarks.
- Watermarking during LLM Training involves changing the LLM parameters to embed watermarks.
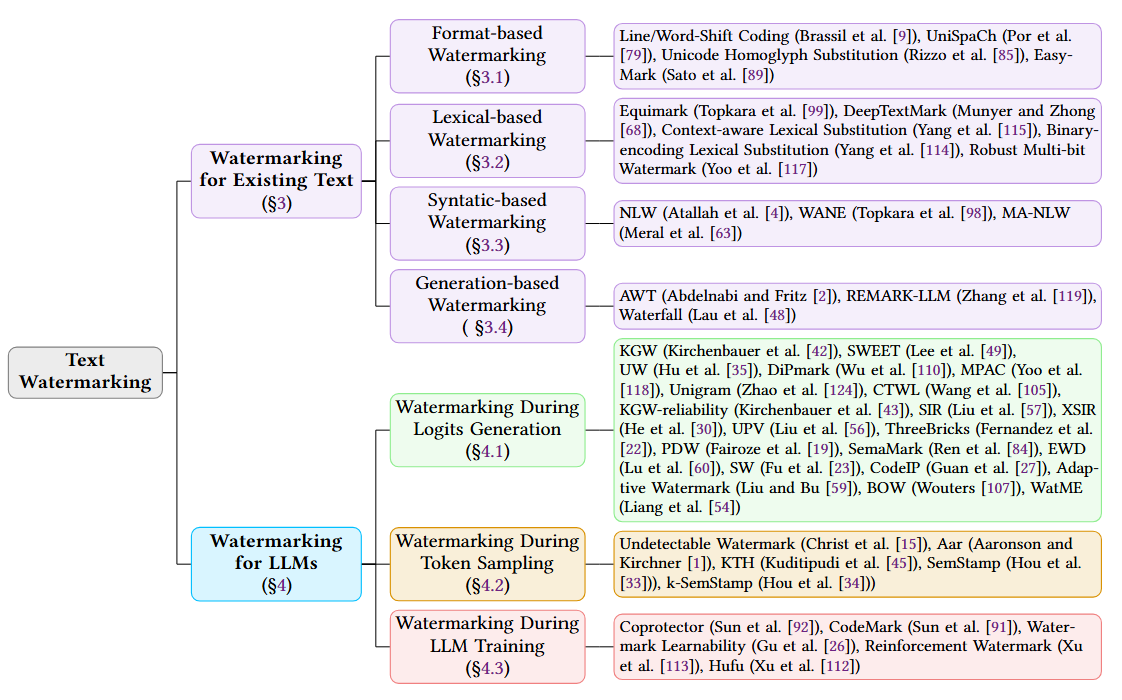
Fig. 2: Taxonomy of Text Watermarking Methods.
Evaluation Methods
We provide summarization of the evaluation metrics for text watermarking algorithms from multipule perspectives: (1) the detectability of watermarking algorithms, (2) the impact of watermarking on the quality of targeted texts or LLMs, (3) the robustness of watermarking algorithms against untargeted and targeted attacks.
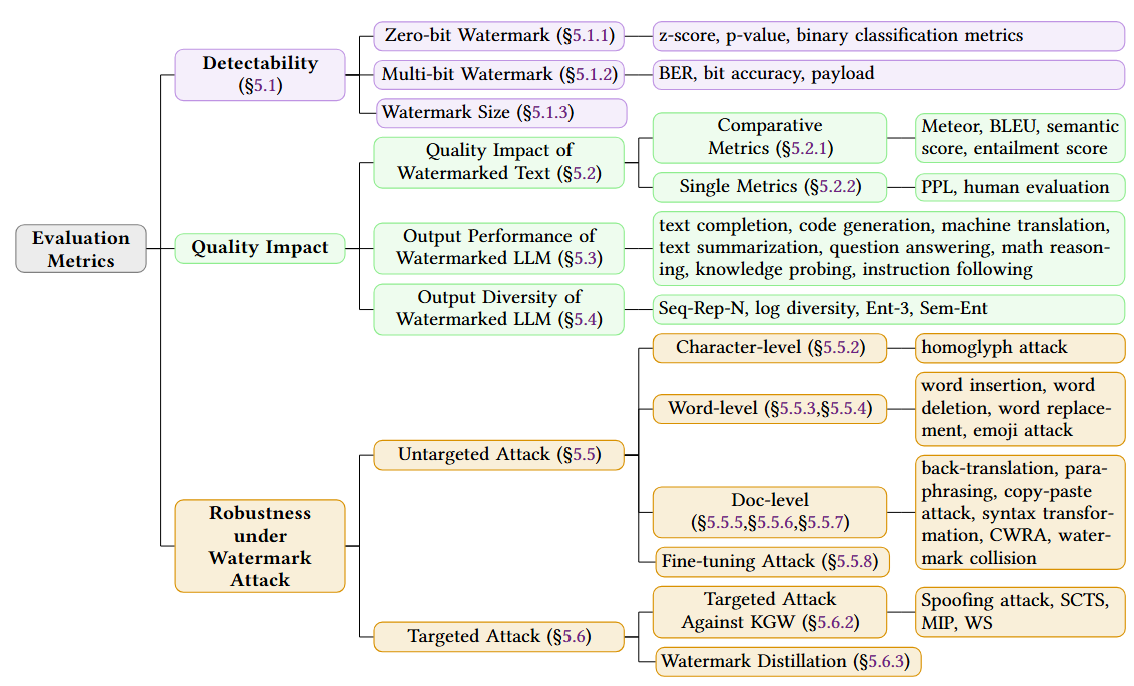
Fig. 3: Taxonomy of Evaluation Metrics for Text Watermarking.
Application Scenarios
Potential application scenarios for text watermarking technology, including copyright protection and AI-generated text detection.
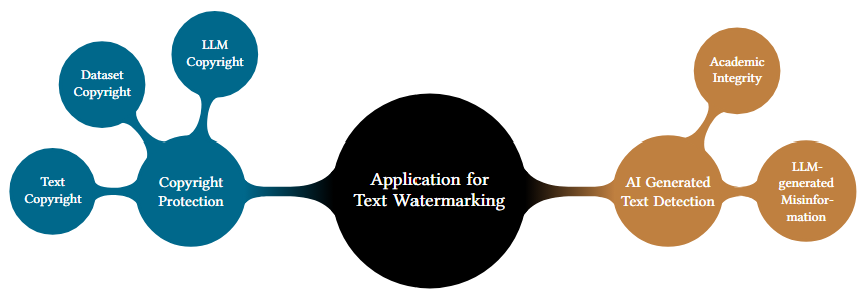
Fig. 4: Taxonomy of Application Scenarios for Text Watermarking.
- Copyright Protection: Ensures creators have exclusive rights to their content and helps identify the source of text.
- Text Copyright
- Dataset Copyright
- LLM Copyright
- AI-Generated Text Detection: Helps identify text produced by LLMs to address issues like:
- Academic Integrity
- Misinformation Detection
Challenges & Future Directions
Current challenges and future directions for text watermarking, including trade-offs in text watrmarking algorithm design, challenging scenarios for text watermarking algorithms, and challenges in applying watermark with no extra burden.

Fig. 5: Taxonomy of Challenges and Future Directions for Text Watermarking.
If you find our survey helpful, please cite it in your publications by clicking the Copy button below.
@article{liu2023survey,
title={A survey of text watermarking in the era of large language models},
author={Liu, Aiwei and Pan, Leyi and Lu, Yijian and Li, Jingjing and Hu, Xuming and Wen, Lijie and King, Irwin and Yu, Philip S},
journal={arXiv preprint arXiv:2312.07913},
year={2023}
}